As an application gains popularity, it naturally attracts a larger user base and introduces new features. This growth results in a steady increase in data generation, which is a positive signal from a business standpoint. However, it also brings architectural challenges, particularly around scaling the database.
The database is a key component in any application, but it’s also one of the hardest to scale horizontally. As traffic and data volume grow, the database can become a bottleneck, leading to slower performance and negatively affecting the user experience.
One solution to this problem is database sharding. In this blog post, I’ll show you how sharding can be used to scale databases horizontally by splitting them into smaller, more manageable pieces known as shards.
What is Sharding?
Sharding is a database architectural pattern that addresses the challenges of handling and querying large datasets. It involves breaking down a large database into smaller, more manageable segments called shards. Each shard functions as an independent database, each containing a portion of the overall dataset.
Sharding is based on the concept of horizontal partitioning, which divides a table’s rows into several smaller tables, or partitions, based on a partitioning key. This key determines how the data is distributed across the partitions. By spreading the data across these partitions, the system reduces the complexity and effort involved in querying and managing large datasets.
Horizontal Partitioning

Database sharding takes the concept of horizontal partitioning a step further. In traditional partitioning, all data groups remain stored within the same system. Sharding, on the other hand, distributes these groups of data—known as shards—across different computers or nodes within a network.
By spreading the data across multiple machines, sharding enhances both scalability and performance. Each machine, or node, handles a portion of the overall data, allowing the system to leverage the combined resources of multiple machines. This reduces the load on any single node and enables the database to efficiently handle larger datasets and higher traffic volumes.
Benefits of Database Sharding
Database sharding offers several significant benefits:
1. Scalability: A primary benefit of sharding is improved scalability. By spreading data across multiple shards, the workload is distributed across different servers. Each shard can handle its own queries independently, which reduces the burden on individual servers. Additionally, new shards can be added as needed without taking the system offline, making it easier to grow as your data and traffic increase.
2. Better Performance: Accessing data in a large, centralized database can be slow, as queries have to sift through many rows to find the right information. With sharding, each shard holds a smaller portion of the total data, allowing queries to run faster by processing fewer rows. This makes retrieving data quicker and boosts overall performance.
3. Increased Availability: In a traditional single-node database setup, if the server goes down, the entire application experiences downtime. Sharding helps reduce this risk by distributing data across multiple servers. If one shard goes offline, the application can continue running using the other shards, improving uptime and reliability.
Types of Sharding
The main goal of database sharding is to evenly distribute both data and query load across multiple servers. However, if the data is not partitioned properly, some shards may end up handling far more data or queries than others. This imbalance is known as a “shard skew”, and it significantly reduces the effectiveness of sharding.
In extreme cases, a poorly implemented sharding strategy can lead to one shard carrying most of the workload while the other shards remain underutilized. This creates a hot spot, where a single node becomes overloaded with traffic.
To avoid skewed shards and hot spots, it’s essential to choose a sharding strategy that ensures data and queries are evenly distributed across all shards, maintaining balanced performance throughout the system.
In the next sections I will cover the most common types of sharding: Range-Based Sharding, Hash-Based Sharding, and Directory-Based Sharding.
Range-Based Sharding
In this approach, each shard is assigned a continuous range of keys, from a defined minimum to a maximum. This approach ensures that the data within each shard is kept in sorted order, which allows for fast and efficient range scans.
To better illustrate range-based sharding, let’s consider a Product table that has been extended with a Price column. By using this Price column as the basis for sharding, we can effectively divide the data into distinct shards based on price ranges.

It’s important to understand that the ranges of keys in range-based sharding don’t always need to be evenly spaced. In real-world applications, data isn’t always distributed uniformly. To ensure a balanced distribution across shards, key ranges can be adjusted based on the actual distribution of data.
However, range-based sharding comes with a potential downside. Certain access patterns can create hot spots. For example, if a large portion of the products in a database fall within a particular price range, the shard responsible for that range might become overloaded with queries and data, while other shards remain underused. This imbalance can undermine the scalability benefits of sharding and result in performance bottlenecks in the overburdened shard. To mitigate this, careful monitoring and adjustments to the key ranges may be necessary.
Hash-Based Sharding
Key-based sharding, also referred to as hash-based sharding, is a method where a specific key is assigned to a shard by applying a hash function.
A well-designed hash function is essential for ensuring a fair distribution of data across the shards. Unlike range-based sharding, which assigns a continuous range of keys to each shard, hash-based sharding distributes a range of hash values across the shards. This technique helps prevent the formation of hot spots and ensures a more balanced workload.
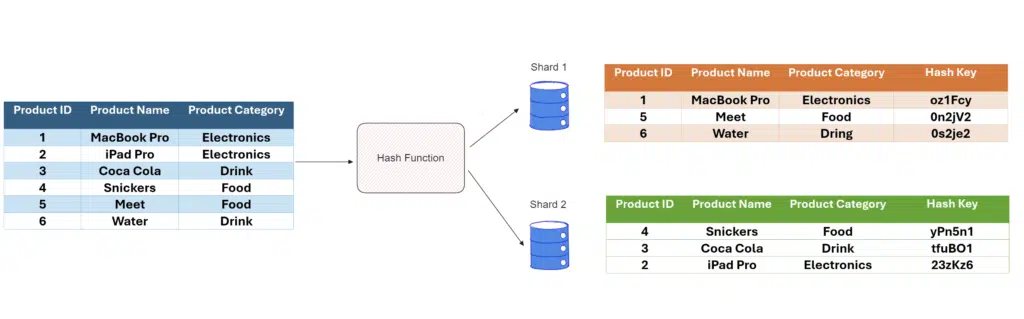
One of the key advantages of hash-based sharding is its ability to evenly distribute keys across all shards. By using a hash function to assign keys, this approach significantly reduces the likelihood of hot spots, where one shard may become overloaded with data or queries. The hash function ensures that the workload is spread out more uniformly, enhancing performance and maintaining balance across the system.
Directory-Based Sharding
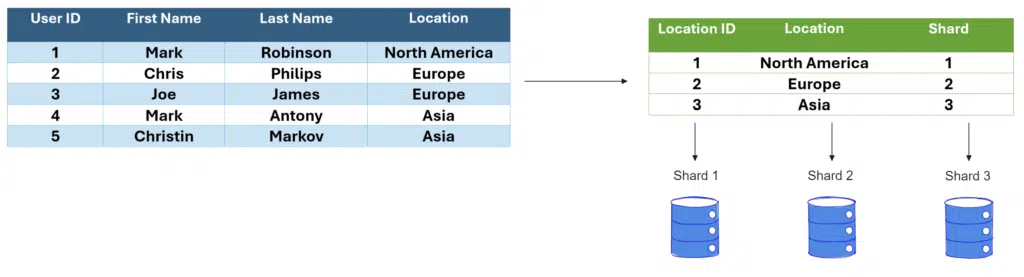
Directory-based sharding is a method that uses a lookup table to determine how records are distributed across shards.
The lookup table acts as an index or directory, mapping each piece of data to the specific shard where it is stored. This table is maintained separately from the shards themselves and is consulted every time data needs to be accessed or stored, ensuring that the correct shard is queried.
For example, in a system where the “Location” field is used as the shard key, the lookup table will map each location to its corresponding shard. This approach provides flexibility in distributing data, but it also requires managing and maintaining the lookup table.
Conclusion
Database sharding is a powerful architectural strategy that enables horizontal scalability by dividing large datasets across multiple servers, or shards. As applications grow in popularity and data volumes increase, sharding can provide significant performance improvements, enhance system availability, and ensure scalability to meet future demands.
However, choosing the right sharding strategy for your specific use case is essential. Range-based sharding is straightforward and effective for data naturally suited to ranges, but it may lead to hot spots if data is unevenly distributed. Hash-based sharding offers a more balanced approach, distributing data evenly across shards and minimizing the risk of overloading any single node. Directory-based sharding provides flexibility and precise control over data distribution, but requires additional complexity in managing the lookup table.
Ultimately, the key to successful sharding is careful planning and ongoing monitoring to avoid imbalances like hot spots and ensure that the system continues to operate efficiently as it scales. When implemented effectively, database sharding allows businesses to scale their applications without compromising performance, reliability, or user experience.
Need help with database scalability or implementing a sharding solution? Contact Trailhead for expert guidance on optimizing your database architecture and scaling your systems seamlessly.



