
The Short Version
The short version is that container technology will allow you to run more apps on the same amount of hardware (in the cloud or on premise). So, fewer real machines, fewer virtual machines (VMs), lower cost for maintaining and upgrading VMS… much the same that the transition to VMs in the cloud has brought to you, but even better.
Which pain are we solving?
In the old days, each time a business app was to be deployed, you would have to purchase a set of machines to run it on, which could cost quite a bit of money, with hardware, operating systems, software licenses, and maintenance costs. These would tend to be over-dimensioned, to mitigate the risk of any poor performance or becoming obsolete too fast. But in reality, they would mainly be under-utilized. Asides from running the actual business app that provided the value you wanted, each machine also ran an operating system. The operating system granted access to the hardware (memory, disk space, processors).

Well as you know, along came VMs. With a VM, something called a hypervisor sits atop the host operating system, and slices up the access to hardware into a set of guest operating systems. These all shared the same hardware – maybe you would give each app one CPU, 2GB of memory, and 1 TB of disk – so you got more out of your capital expense. Importantly, these apps and their guest operating systems were isolated from each other, each thinking they had their own hardware, and couldn’t bring each other down.

This was a big improvement. Now you could wring a lot more out of the same hardware. Along came a host of VMs ranging from VMWare to Microsoft Hyper-V. And along with these came amazing tools and technology for managing these VMs, especially in the cloud. You could spin up a VM in no time, and pay for usage of resources, scale farms of VM’s elastically to meet peak needs, do your development and testing on temporary cloud VMs, etc.
However, there were still a lot of wasted resources in this picture. Given that what we really care about is running our apps, the large set of duplicated guest operating systems is a problem. Each one comes with a lot of cost: you need operating system licenses, they take up a a good percentage of your hardware resources just to run (memory, CPU, disk), leaving much less resources for your apps.
Containers to the rescue:

A Container slices up operating resources in the same way a Hypervisor slices up access to hardware. It gives access to a protected process space (with memory and threads), file system and network stack, where each app is protected from the others, but without the overhead of a whole guest operating system for each. You can now run way more apps on the same hardware, and pay for way less operating systems, never minds the costs of maintaining and upgrading them.
What is Docker?
Just as there were originally different operating systems, different hypervisors, different clouds, there are also different container systems. One of the more popular ones is called Docker.
Docker originally only supported Linux, so the apps running would also have to be Linux apps. But Microsoft jumped in early, and brought Docker technology to Windows and Azure, so now you can run Docker on Windows as well, and run Windows apps.
You can run the Docker Engine on your local development machine, on your networked servers, in all kinds of data centers, and in the Azure or AWS or other clouds. Recently, a whole lot of effort is going into tooling for Docker, to make it just as easy to deploy your apps to Docker as it is to deploy them to a physical machine or a VM, running anywhere. At that point, why would you want to do anything else? Why pay for an extra OS license for each app? Why have to maintain the OS of a VM for each app? Why waste half of your VM or real resources on OS processes, cutting your performance? It’s a no brainer.
One minor point before I continue… the pictures above look like all the apps and OSes are homogenous, but of course they are not: you can have a Linux and a windows VM on the same hardware. However, the Docker apps are. You run windows workloads on windows Docker hosts, and Linux payloads on Linux Docker hosts.
Containers
So what exactly is a Container?
The analogy comes from the shipping industry. Before the advent of standardized shipping containers, loading cargo on to or off of ships, trucks and trains was mayhem! Cargo came in all kinds of bags, boxes and pallets, and in all kinds of shapes and sizes. But with containers, you can put your stuff in a standard container, and it can be loaded, unloaded, moved around, all over the world, using standardized machines and procedures, whether you are shipping peanuts, cars or art.

The same goes for software containers: you can ship your app to a range of different destinations, from your laptop to Amazon AWS or Azure, to dev, QA or production, in a container, that makes your app behave the same way no matter where it gets shipped!

Images
There are tools and processes used to make your app into a container, i.e. to Dockerize it. These tools are very smart about the use of space: since many apps will be sharing many of the same binaries (for instance, 5 web apps or APIs might all need a web server), these common images are actually shared for real, and only need to be deployed once, even when used by tons of containers.
For instance, you might have 2 apps that both need IIS running on .NET. You would layer this as follows, and when deployed, only one copy of the IIS and the .NET nanoserver image would be actually deployed. This saves disk space, and it saves network bandwidth when deploying Containers.

Docker uses a smart layered file system, where the underlying layers are read only, and only the top one is writable. When you try to write to an underlying layer, a copy of it is created in your top layer, but the underlying ones remains unchanged. Since they never change, they can be shared. This was already built in to Linux – Microsoft had to pull a few tricks and do some additional work on Windows to enable these features.
A Container is described by a Dockerfile that explains how to take a base image and add to it what you need to do. For instance, download and install certain Nuget packages, run certain commands or scripts, write certain configuration files. These commands could also be to do with provisioning or configuring different environments, like DEV, QA and PROD. Basically, you take your underlying layers, your specific app code and configuration, combine them in a Dockerfile, and you have the instructions to build your Container. The Container is actually instantiated with Docker commands, locally or remotely, that download the images in your layers, start a new container, assign it operating system resources, and run your commands, usually resulting in some process like a Web Server or a Database Server waiting for input.
Note that in ALL these diagrams above, from the beginning of the article, your app is unchanged. It is the same code, the same binary… nothing needs to be done for it to run in a container.
Now that you see how you can package you software into containers, there are a few more even more powerful concepts coming down the road.
Clustering
Likely in the last few years you have become accustomed to building stateless apps that can be scaled out in a web farm, using maybe AWS and ELB, or Azure App Services. You need some kind of smart load balancer, and you need your apps to be stateless, and for failover to happen automatically. Sometimes (in the context of databases or Redis) you use the concept of a high availability cluster. The concept in Docker is called Swarm.

In Swarm, you can deploy your app to a number of nodes, say 10, running on a number of Docker engines. Those engines can be on different machines, or even in different data centers – even some in Azure and some in AWS! If any one of those nodes dies (crashes, or is on a machine that dies, or loses a network connection), the other nodes automatically take over the load, and create a new node to replace the missing one. You do this declaratively: you say you want 10 nodes. You don’t have to micromanage any of the details of the configuration, or the failover itself. Swarm makes sure you will always have the number of nodes running that you specified.
With Swarm, some of the nodes are managers (typically 3 are). These managers communicate with each other and make sure they are alive and well, and that the required number of nodes is running. They also run regular node workloads (containers). So out of 10 nodes, 3 may also be managers.

This is all accomplished in software, internally inside the Docker Swarm Engine. You don’t need your smart load balancers to know about it at all. Technically you don’t even need a load balancer, Swarm will adjust requests to the right container to balance the workload all by itself. Of course, it helps if you have some piece of software or hardware that maps the same IP across a range of Docker engine hosts, but technically just one mapping is enough, the rest happens internally.
Orchestration
The other concept is Orchestration.
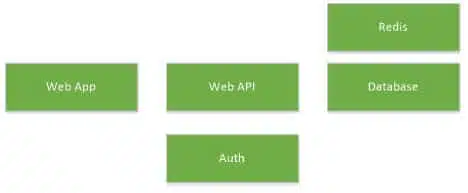
A typical mordern business app is not a monolith, it is a set of discrete parts, possibly each one written in a different language. For instance, we might have a Single Page Application (SPA) written in HTML 5 and Angular, (Web App) calling a REST Web API written in C# using .NET Core and Entity Framework Core, authenticating against a directory service to get a bearer token that is passed to the Web API. The Web API might uses a Redis cache and a MS SQL database.
This kind of architecture is becoming even more prevalent with the advent of things like micro services.
The apps all communicate with one another; typically HTTP over SSL on port 443 between the Web App and the WebAPI and Auth, and maybe port 1433 TCP to the MS SQL database, and port 6379 for Redis. They run in different containers, possibly on the same, but more likely on different machines. However, the web app doesn’t need access to the DB port or Redis, nor does the Auth app need access to the MS SQL DB.
With orchestration, you describe how all these containers fit together, and what their communication needs are. Then, when you go to deploy, all this is automatically configured for you. The lingo for this is Docker Compose:

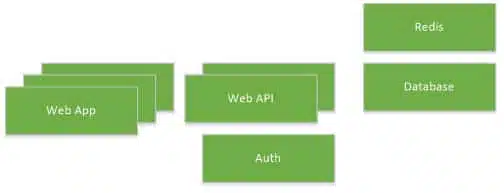
Docker Compose and Docker Swarm come together when you describe how your containers fit together, but also how many instances of each you need running. Maybe you want a set of 3 SPA frontends, 2 Web APIs, and one each of Auth, Redis and MS SQL.
Docker Hub and Repos
One last concept to mention here is Docker Hub. Remember I talked about the standard image layers for say IIS or MS SQL or .NET? Well, you can download these from DockerHub at https://hub.docker.com/, just as you would download packages from Nuget. The images are stored in different repositories, some are public (like Microsoft’s) and some are private = yours! You can create your own images and save them to your private enterprise DockerHub repo (just as you can save code to your private GitHub). And for those of you too paranoid for that, there is also a version you can run inside of your corporate firewall. Below you can see the official Repos for Redis, Ubuntu, Mongo DB and more. And of course all these technologies support versioning.
Now I hope you have a basic understanding of what Containers are, and what Docker in particular is. It is evolving extremely fast, is open source, has broad industry and community support, and it is going to save you a lot of money and headaches, while being fully backward compatible with your existing business apps.
So in my opinion it is high time to start learning about it; have your IT people and software teams start reading and learning on line, and try some in house projects using Docker for your development and QA, so you can hit the ground running.




