Being able to exchange data between the front-end and back-end of web applications is a primary component of their architectural design. For enterprise projects, neither part of the application should trust they data they receive. For example, hopefully it’s obvious that the back-end must validate every value that comes to its endpoints from the front-end. However, the front-end developers must also write their code to be fault tolerant based on different responses and data formats returned from the back-end, including unexpected responses.
A common solution to this problem is called data mapping. The question is, how deeply should we map and parse an HTTP response’s data, and what checks should we apply to the mapping? We could simply rely on the data contract that was agreed upon before starting development and just do very simply mappings between the back-end and front-end data format, such as:
<frontEndPropertyName> = <back_end_property_name>But what if, for some reason, the back-end returns a string where an array is expected? Or, what about an array of strings being returned instead of array of objects? Or maybe just a null value instead of an object? Certainly, every JavaScript developer has been faced with that common JS error: ‘Cannot read properties of null (reading '<propertyName>')’. These error can occur so easily, and when it does, it often crashes the application (or at least a certain part of it).
Why Data Mapping the HTTP Response?
Let’s consider two facts:
- Most web applications are based on JavaScript as a programming language, and
- JavaScript is not tolerant to errors caused by unexpected data types.
These conditions clearly define the main reason why we need of data mapping: to make the front-end code more stable and free of risk of failure by converting any API response format to a more predictable data that we can used throughout the web application.
Besides ensuring better security and stability of the application, data mapping helps us to achieve two additional goals:
- To create a view-specific data model with all the required \properties and methods for our application from the moment the response is parsed, and
- To reduce dependency of the front-end’s data model from the back-end data model and its naming convention or data formats.
Advantages of Data Mapping Response
The advantages of data mapping are quite straightforward and directly related to the purposes above. It gives us such advantages as:
- Response validation–stabilizes and secures the app’s performance, providing a more successful user experience
- The ability to supply the application with predictable data of a known format. We can reduce extra checks in templates and prevent complicated conditionals and rendering conditions. This will improve an app’s performance for the end user
- The ability to define all calculated values that our application needs at the moment of parsing the server response. This will make a lot of data transformations in templates unnecessary–another step to increase performance. For example, if the app needs a full user name for a view template, then it’s better to create it once from the first name and last name properties rather than concatenate them over-and-over in a React functional component during every rendering cycle
- since we use defined naming throughout the application we don’t depend on back-end properties’ naming. It make us free to manipulate them according to naming convention. If any property name or even data transfer object (DTO) format changes it doesnt make us to change names of previously defined variables and view templates logic. It is enough for us just to adjust logic inside function that maps the response
- ability to add methods to view data model and concentrate most of the logic inside the model
- ability to mock back-end data easily and provide front-end and back-end development almost independently
- extra advantage for TypeScript – we can use data model class as a type
- extra advantage for Angular developers (or, to be more precise, for those who use RxJS) – we can combine several HTTP requests and map responses to one model (similar approach is described in this post)
Concerns About Data Mapping Responses
Concerns about response data mapping mostly focus on implementation and performance.
The first concern, implementation, is because developers sometimes over-engineering. It is quite easy to get carried away with modern TypeScript features and write tons of code with overloading of constructors, decorated properties and methods, and so on. Besides creating extra, unnecessary work, thus will negatively impact the performance of the application. Better to keep it simple.
The second concern is the performance of the mapping. It depends on a depth of the check we apply to a response’s format and properties (if it’s an object) or elements (if it’s an array). Moreover, if we expect an array of object, we probably want to ensure that every element is an object, contains all the properties we are interested in, and that they match the required data type. A natural question is how much time will it take to process all these checks and whether it is worth it.
Approaches and Best Practices
Taking into account the concerns about performance and implementation along with general JavaScript best practices, we can define some common rules to keep all of our checks as simple and reliable as possible, without over-engineering them. I’d suggest best practices like the following:
- Use simple arrow functions as response mappers and view model classes to parse an object if we expect the object. That allow you to do initial response checks and allocate the logic inside the class constructors
- Use a common JS approach to check if DTO is an object:
const response = dto && typeof dto ===‘object‘?dto : {}
That allow us to avoid a known JS bug when simple check like typeof dto give us ‘object’ if dto is null
- Do not use array methods – every predicate arrow function creates its own closure and requires memory allocation. Use while.. or for.. loops – they are fast and optimized
- Check if data is an array using Array.isArray() static method
- Initiate all calculated properties only once, that allows us to avoid getters – they can impact rendering performance a bit
Code Example
Let’s presume that we expect the back-end to return a response like the following;
interface UserDTO {
firstName: string;
lastName: string;
age: number;
address: {
country: string;
city: string;
street: string;
building: number;
apartment: number | null;
}
}
interface ResponseDTO {
users: UserDTO[]
}Our front-end application needs its own model, which could look like this:
interface UserModel {
firstName: string;
lastName: string;
fullName: string;
age: number | string;
address: {
country: string;
city: string;
}
}Our response mapper can be defined as arrow function:
const mapper = (response: ResponseDTO): UserModel[] => {
const result = [];
if (
!response ||
typeof response !== 'object' ||
!Array.isArray(response.users)
) {
return result;
// or we can return null – it depends on our front-end business logic in any particular case
}
const { users } = response;
for (let i = 0; i < users.length; i++) {
result.push(new UserModel(users[i]));
// or new UserModelDeepCheck(user[i]), see below
}
return result;
};The main question is how deeply we should do check the model for properties. Depending on your needs, there are two approaches, which I’ve outlined below.
Option 1 – Lightweight Example (less fault-tolerant)
class UserModel {
constructor(rawData) {
// guarantee that the data exists and has appropriate format
const data = rawData && typeof rawData !== 'object' ? rawData : {};
const {
firstName, lastName, age, address: rawAddress
} = data;
// guarantee that the data exists and has appropriate format
const address = rawAddress && typeof rawAddress !== 'object' ? rawAddress : {};
const { country, city } = address;
this.firstName = firstName;
this.lastName = lastName;
this.fullName = `${firstName} ${lastName}`;
this.age = age;
this.address = {
country,
city
}
}
}Option 2 – Hardened Example (more fault-tolerant)
class UserModelDeepCheck {
constructor(rawData) {
// guarantee that the data exists and has appropriate format
const data = rawData && typeof rawData !== 'object' ? rawData : {};
const {
firstName, lastName, age, address: rawAddress
} = data;
// guarantee that the data exists and has appropriate format
const address = rawAddress && typeof rawAddress !== 'object' ? rawAddress : {};
const { country, city } = address;
this.firstName = typeof firstName === 'string' ? firstName : '';
this.lastName = typeof lastName === 'string' ? lastName : '';
this.fullName = this.firstName && this.lastName ? `${firstName} ${lastName}` : '';
this.age = typeof age === 'number' ? age : 'n/a';
this.address = {
country: typeof country === 'string' ? country : '',
city: typeof city === 'string' ? city : ''
}
}
}As you can see, you can perform more checks or fewer checks, with a balance between the performance of your code and risk of a crash due to unexpected data. Which one you use depends on the business logic of your application, and on how any particular model will be used.
Benchmarking of Different Types of Mapping
Lets try to measure time consumption of the two options above using an array of 100,000 user DTOs. I will create two separate functions – one for light check and one for deeper check. This allows me to do checks on both cases as ‘cold’ functions for the first round, and as already compiled functions for the second round. My results are show in the screenshots below.
With Normal CPU performance
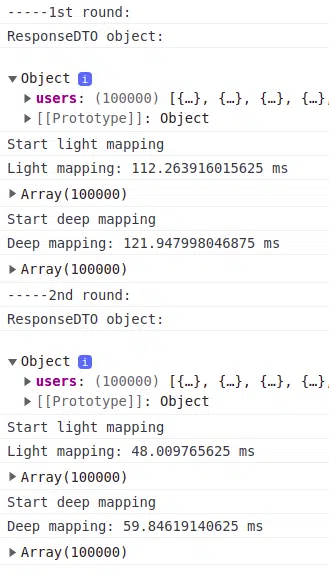
With CPU Performance Slowed Down by 6 Times

Conclusion
As we can see, the results are interesting. No result was over 200ms, but deep mapping these objects took almost twice longer for the worst case scenario.
We should keep in mind, though, that our example user DTO and user model both contain a short list of properties. For real-world development, we should make a decision about the depth of checking that is needed with the performance-versus-crash-risk balanced.