The other day I was faced with this task, and ran into quite a few issues on the way. Despite intense googling and corresponding on the AWS forums, I ended up having to resolve it myself, so by blogging about it I hope it might make someone else’s experience smoother.
RDS
RDS (Relational Database Service) is Amazon’s SQL Server as a service solution, much like Microsoft Azure DB. In fact, it is more generic, you can choose which database engine to implement RDS with, including Oracle, MSSQL and more:

Since you are using a service, not an actual server, you cannot Remote Desktop into the instance, you don’t have control over the machine or VM that the SQL Server resides on. However, you can use many of the features in SQL Server Management Studio (SSMS):

As you can see, the instance comes with the standard system database, including msdb which will look at later.
You can create multiple databases on the instance, and you can set up all kinds of nice high availability and fault tolerance scenarios.
Restoring a backup
Typically, you restore a backup to SQL Server by placing the .bak file somewhere in the local file system of the SQL Server, and then using the restore Task in SSMS, or the restore command in Transact SQL, to specify that file as the source for the restore. Since we cannot access the local file system of the SQL Server, that won’t work.
Amazon S3 to the rescue! Amazon has an add on where you can actually upload a .bak file to a bucket in the Amazon cloud storage, S3, and reference it from there.
Uploading the backup file
I ran a regular backup from my on premise SQL Server, no special options. Then, I created an S3 bucket to place it in. As you can see, the restored files are quite large, 1.4 GB in one case. Make sure you create the bucket in the same region as your RDS instance!
To get the .bak file uploaded, I first tried to use the built in Web UI in AWS Console to upload the file, but it kept failing half way through. Reading about this problem, it seemed quite common. So instead I downloaded and installed the free trial version of Cloudberry Explorer, which has S3 support. Once in the Explorer, you add an S3 bucket, and will need the Access Key and Secret Key that you got from AWS Console when you first set up your security credentials (Services, IAM, Users, Security Credentials).
Setting the option group
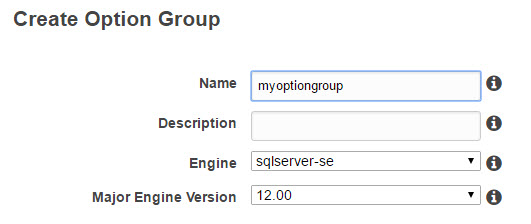
To enable restoring form (or backing up to) an S3 bucket, you need to replace the standard option group of your RDS instance with one that includes the SQLSERVER_BACKUP_RESTORE option.
To do this, go to Option Group, Create, choose a descriptive name, your SQL engine and version,
Next, choose Add Options, and add SQLSERVER_BACKUP_RESTORE
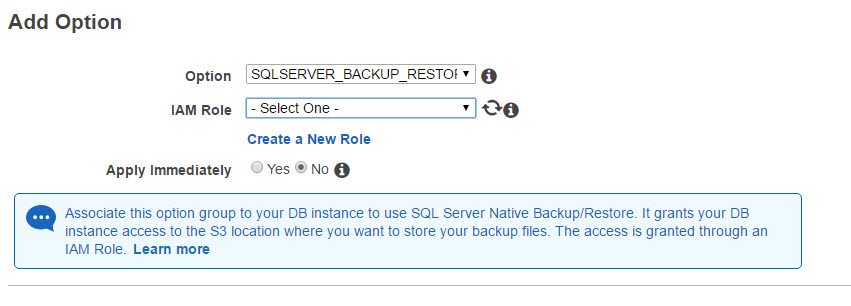
You will need to create a new IAM Role, and specify the name of the bucket you created for backup. Also, choose Apply Immediately.
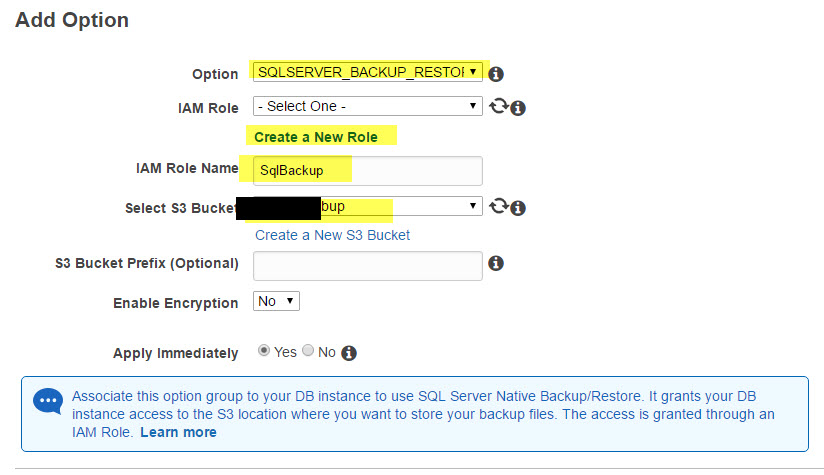
Once the Option Group has been created, go back to your RDS instance, and choose to Modify it. Scroll down to the Option Group section, choose your new option group, check Apply Immediately, and save.

This change will take a few minutes to apply, and once done, your RDS instance will have some new Stored Procedures in msdb that will allow you to backup and restore to AWS S3 buckets.
Running the restore command
Once I had the option group attached, I went back to SSMS, and opened a query window in the msdb database of my instance. From here, you will want to execute a command like this:
exec msdb.dbo.rds_restore_database
@restore_db_name=’yourdbname’,
@s3_arn_to_restore_from=’arn:aws:s3:::yourbucket/yourfilename.bak’
Note that yourdbname is the name of the database you are restoring to, and it cannot already exist! In other words, the command creates the database for you. yourbucket/yourfilename.bak is the full bucket path and filename in S3.
I ran into one other problem here where my user did not have permission to run the restore command. Luckily, I had an admin login to SSMS so I could grant myself that permission in msdb:
GRANT EXECUTE ON dbo.rds_restore_database to [myusername]
The restore command returns a Task ID, which you can use to monitor the progress of the restore:
exec msdb.dbo.rds_task_status @task_id = 8

The strange error
So to the real issue I ran into after figuring out all this stuff! When I ran, I got an error, with this interesting message:
RESTORE requires MAXTRANSFERSIZE=1048576 but 65536 was specified.
RESTORE FILELIST is terminating abnormally.
Aborted the task because of a task failure or a concurrent RESTORE_DB request.
Invalid attempt to read when no data is present.
Some Googling showed that the Transact SQL restore command does indeed have a MAXTRANSFERSIZE parameter. Sadly, the AWS rds_restore_database procedure doesn’t, and there is no way to modify what it does internally.
What didn’t work
My first attempt was to issue the backup command with a specified MAXTRANSFERSIZE parameter, and then use that .bak file instead to restore. In fact I tried 3 versions: the original command, with no value, and the two mentioned in the error message, 1048576 and 65536. All these failed with the same message.
I also tried changing the minor version of the RDS instance to SQL Server 2014 SP2 (using a new Instance), hoping maybe this was a bug fixed in SP2. Nope.
Next, I changed the version of my source database to SP2, and did the backup again. Same result.
I tried backing up and restoring from my instance to an S3 bucket, and that worked (more on the restoring below).
I logged a ticket in the forums, which got one response, but I had already tried that and it didn’t help.
What worked
I finally randomly figured out what the problem might be, and it turns out I was right. The source database had a FILESTREAM group (which wasn’t even in use). So I removed it, and then redid the backup. Now my restore worked flawlessly! It turned out that the error message had pretty much nothing to do with the real problem!
Gotcha with the name of the MDF
I did run into one more gotcha, after the restore command made it past the initial error. It failed a few minutes later saying that dbname.mdf was already in use. I already had a database named dbname, and it had gotten the default filenames dbname.mdf and dbname.ldf for the transaction log. Even though I specified a different database name for the restore, the original backed up database had also use dbname.mdf. So if you want to restore two copies of the database, with two different names, you can’t. You would need to, at the source, detach, copy, rename and attach the renamed mdf and ldf files to a new database, and then back them up with their new filenames. It seems like that could be fixed with the restore command! You will run into the same issue of backing up from an RDS instance to a S3 bucket, and then trying to restore that backup to the same instance and a different DB name, not possible.
Gotcha with the user names
Finally, I ran into the usual issue with transferring a DB from one SQL Server to another… the good old login/user mismatch. I ended up making the db Admin account the DBO of the restored database, then deleting the original user that was DBO from that database. Then I created a login for that user, and made it the DBO of the restored database. Always a pain! But not specific to RDS.
Final thoughts
After jumping through hoops, I was finally able to restore a regular MSSQL backup to RDS, which is a welcome addition to the powerful features of RDS. The RDS command could use some better error handling and flexibility. I hope having all this info in one place will save you some time should you go this route.
At Trailhead we have tried all kinds of approaches to moving data between on premise and cloud (Azure DB, Azure VM and AWS) versions of SQL Server, if this is something you are struggling with, we can help!




